Does Google Index CSV files on SERP? For years, data professionals have relied on CSV files to efficiently store and exchange tabular information between databases, applications, and beyond. However, a major open question remained – could search engines understand and index the contents within these comma-separated value formats? Now we have a definitive answer, thanks to a significant update rolled out last month (August 2023), by the world’s leading search provider, Google.
What is a CSV File?
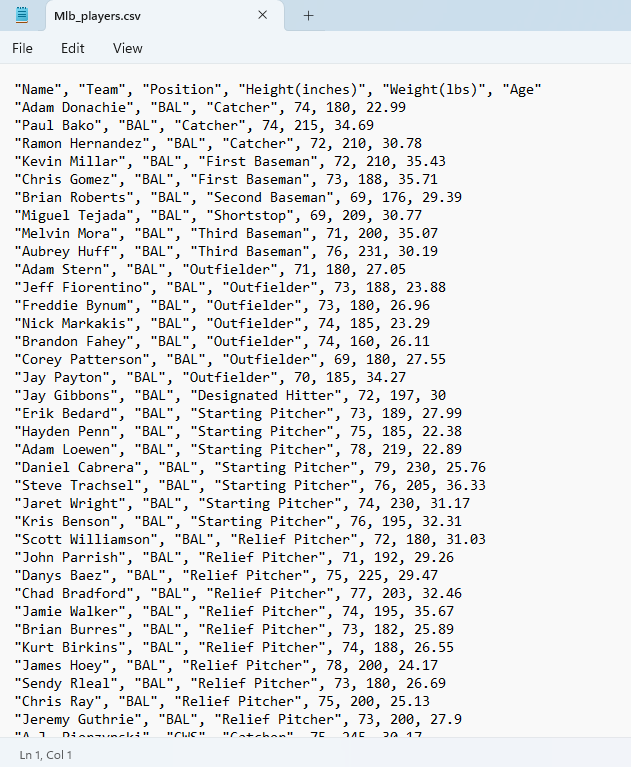
A CSV (comma-separated values) file is a simple format for storing tabular data like database records or spreadsheet information. The name describes its basic design – each row constitutes a single record, with each field value separated by commas.
Some key points about CSV files:
- The format saves information in plain text form, making CSV easy to export, import, and exchange between different programs and systems.
- CSV files can be opened and edited with any basic text editor or in popular office suites/spreadsheets under the .csv extension.
- Each row of the CSV represents one complete data record from the database or spreadsheet. Columns correspond to field names, while rows contain the individual field values.
- The first row often contains the field names or headers to label each column. But this is not strictly required for CSV syntax.
- Commas are the default delimiter between values, but other characters like tabs or pipes can be substituted depending on the software or standard used.
- CSV’s simple text structure sacrifices some functionality for ultimate cross-platform compatibility between programs. However, it remains ideal for transferring tabular data between databases and applications.
History of CSV Files
CSV (which stands for comma-separated values) has its origins in word processing and spreadsheet software from the 1980s. By representing rows and columns as plain text with commas delimiting each field, CSV provided a simple yet effective means of transferring data between programs in a readable format. Over time it became a ubiquitous standard for moving information between disparate systems. Nowadays, CSV remains one of the most popular choices for exporting data from databases and analytics tools due to its cross-platform compatibility and human-friendly design.
The Elusive Issue of Search Indexing
While CSV excels at portability, its plaintext roots come with limitations. For instance, search engines historically had not demonstrated an ability to accurately parse tabular data dumps and discern field labels vs. values. Resultantly, many organizations and individuals uploading CSVs assumed the contents would remain invisible to search engine crawlers. This posed problems for discovery and meant useful datasets risked getting siloed rather than shared through search.
Google Is Indexing CSV Files Officially
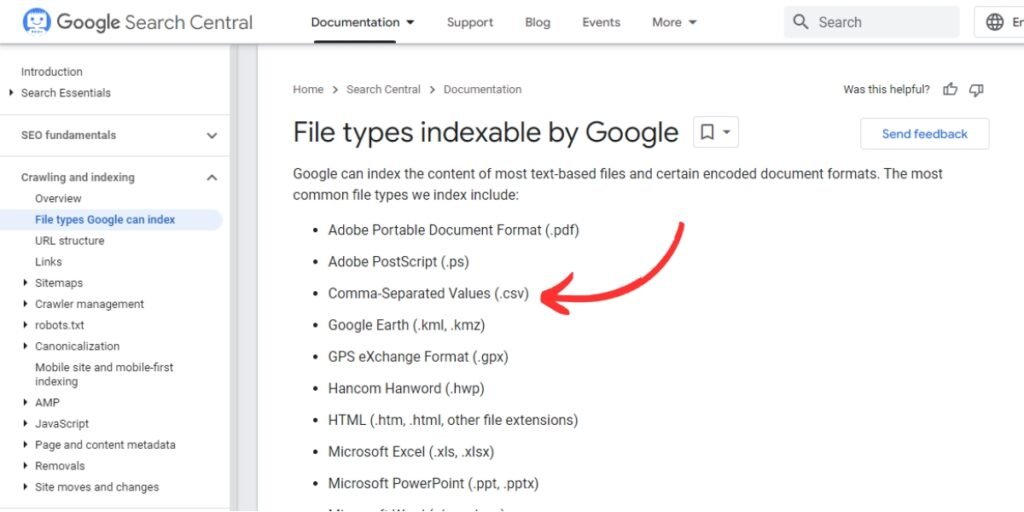
All that changed recently when the tech giant quietly added “CSV” to its list of indexable file types– implying these comma-separated files could now be indexed. Intrigued by such a significant development if true, industry experts reached up directly to Google Search expert John Mueller for confirmation on X(formerly Twitter). Mueller verified via Twitter that CSV indexing was no mere technical documentation update, but reflected a new capability rolled out within Google Search itself. This confirmation lifted the veil on one of the lasting mysteries around CSV searchability.
The What and Why of Google’s Move
With CSV formally included in Google’s indexing programming, the search leader can recognize the tabular structure of these documents and read each cell value when crawling publicly available CSV archives. But why make this particular enhancement now? For one, the rise of open data mandates and data journalism has led to a proliferation of databases shared online via CSV dump.
Untappable by search, such valuable information repositories risked obscurity. By welcoming CSV into the fold, Google helps connect users to these burgeoning “data web” resources. It also aligns with the company’s broader aims of promoting openness, and innovation and using AI to unearth patterns across all digital artifacts.
How it Benefits Data Professionals
Naturally, this added support for CSV indexing will benefit a wide range of professionals who rely on the format for managing and disseminating data holdings. For archive administrators and data librarians, it ensures important public records and statistical series stored as CSV achieve maximum findability. Analytics firms and journalists publishing datasets to underpin their insights gain a search-friendly distribution channel. Even internal-facing CSVs used for CRM and business intelligence take on new discoverability within enterprise intranets now equipped for CSV crawling. In every case, content providers can rest assured relevant keyword searches will lead inquirers directly to the needed databanks.
Optimizing CSVs for Search
While Google can read CSV tables, publishers should take familiar search engine optimization best practices into account. Include descriptive metadata and meaningful header fields. Structure field names and contents for comprehension. Provide additional context and categorized listings. Even simple amplification like descriptive filenames and sitemaps can aid crawling. Proper optimization, when adopted, will translate efforts spent on a CSV into high rankings and traffic for informing the public.
Conclusion
After years of ambiguity, the saga over CSV indexing has reached a resolution that search marketers and information professionals will appreciate. By opening its virtual doors to this ubiquitous data format, Google fulfils a key requirement for web-based discovery. How search engines handle CSVs going forward remains an evolving story. But for now, data holders can breathe easy knowing spreadsheets hosted online stand a fair chance of enlightening curious visitors on virtually any topic via Google Search. Discovery of and engagement with datasets is poised for a dramatic uptick.
Articles you would like to read: